Open AI Glide Menghasilkan Gambar Fotorealistik – Salah satu bidang AI paling aktif dan menarik di tahun 2021 adalah pembuatan teks-ke-gambar. DALL-E , versi parameter 12 miliar dari model bahasa transformator GPT-3 OpenAI yang dimaksudkan untuk menghasilkan gambar fotorealistik menggunakan keterangan teks sebagai isyarat, dirilis pada Januari 2021. Performa E yang luar biasa dari DALL menjadi hit instan dalam Kecerdasan Buatan industri, dan juga menerima liputan media arus utama yang luas. NVIDIA meluncurkan GauGAN2 berbasis GAN bulan lalu, yang meningkat sepuluh kali lipat dari pendahulunya dalam hal menghasilkan visual yang sebelumnya dianggap tidak mungkin dari perintah teks. Tidak mau kalah, peneliti OpenAI memperkenalkan GLIDE minggu ini, model difusi yang memberikan kinerja yang sepenuhnya mengungguli model mereka sebelumnya dan yang diungkapkan oleh Nvidia sambil menggunakan kurang dari sepertiga parameter dan menjadi lebih efisien secara umum.
Meskipun sebagian besar gambar dapat dideskripsikan dengan kata-kata, membuat gambar dari input teks memerlukan pengetahuan khusus dan waktu yang lama. Mengizinkan agen AI untuk menghasilkan gambar fotorealistik dari permintaan bahasa alami tidak hanya memungkinkan orang untuk membuat materi visual yang kaya dan beragam dengan kemudahan yang belum pernah terjadi sebelumnya, tetapi juga memungkinkan penyempurnaan berulang yang lebih sederhana dan kontrol halus dari gambar yang dibuat.
Penelitian terbaru telah menunjukkan bahwa model difusi berbasis kemungkinan juga dapat menghasilkan gambar sintetik berkualitas tinggi, terutama jika digabungkan dengan pendekatan panduan yang menyeimbangkan variasi dan ketepatan. OpenAI menerbitkan model difusi terpandu pada bulan Mei , yang memungkinkan model difusi bergantung pada label pengklasifikasi.

Bagaimana cara kerja GLIDE AI?
GLIDE memajukan pekerjaan ini dengan membawa difusi terpandu ke masalah pembuatan gambar bersyarat teks. Para peneliti menyelidiki dua strategi panduan yang berbeda: panduan CLIP dan panduan bebas pengklasifikasi , setelah melatih 3,5 miliar parameter model difusi GLIDE yang menggunakan encoder teks untuk mengkondisikan deskripsi bahasa alami.
CLIP adalah metode yang dapat diskalakan untuk mempelajari representasi bersama teks dan gambar yang menghasilkan skor yang menunjukkan seberapa dekat suatu gambar dengan keterangan. Para peneliti menggunakan strategi ini untuk mengganti pengklasifikasi dalam model difusi mereka dengan model CLIP yang memimpin model.
Sementara itu, classifier-free guidance adalah strategi bimbingan model difusi yang tidak memerlukan pelatihan classifier terpisah. Ini memiliki dua fitur yang menarik: 1) Memungkinkan satu model untuk menggunakan pengetahuannya sendiri selama panduan daripada bergantung pada keahlian beberapa model kategorisasi; 2) Menyederhanakan panduan saat mengkondisikan informasi yang sulit diprediksi.
Asesor manusia lebih memilih output gambar panduan bebas pengklasifikasi untuk kesamaan fotorealisme dan teks, menurut penelitian tersebut.
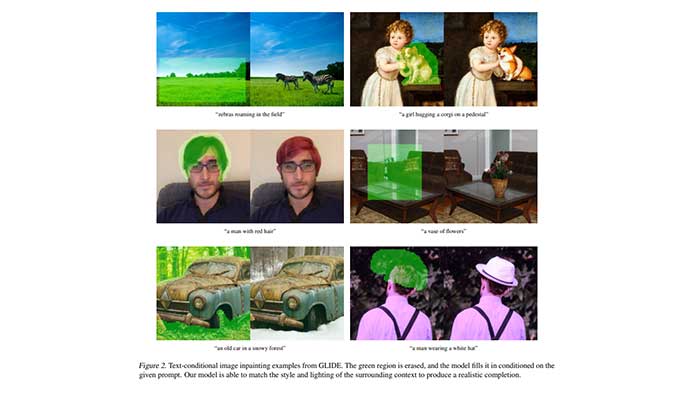
GLIDE menghadirkan foto beresolusi tinggi dengan bayangan, pantulan, dan tekstur realistis dalam pengujian. Model juga dapat mencampurkan banyak ide (misalnya, corgis, dasi kupu-kupu, dan topi pesta) sambil menetapkan properti ke barang-barang ini seperti warna.
GLIDE dapat digunakan untuk mengubah gambar yang ada menggunakan perintah teks bahasa alami, selain menghasilkan gambar dari teks. Ini termasuk memasukkan objek baru, menambahkan bayangan dan pantulan, melakukan lukisan gambar, dan sebagainya.
Sketsa garis sederhana juga dapat diubah menjadi gambar fotorealistik, dan kemampuan produksi dan perbaikan tanpa sampel GLIDE untuk skenario rumit sangat mengesankan.
Meskipun ini adalah model yang jauh lebih kecil (3,5 miliar vs. 12 miliar parameter), membutuhkan penundaan pengambilan sampel yang lebih sedikit, dan tidak memerlukan penataan ulang CLIP, penilai manusia menyukai gambar keluaran GLIDE daripada DALL-E.
Selain melukis, model difusi dapat membuat gambarnya sendiri dalam berbagai gaya, seperti gaya Van Gogh atau gaya lukisan tertentu. GLIDE juga dapat membuat konsep pada corgi, seperti dasi kupu-kupu dan topi ulang tahun, sekaligus menetapkan properti untuk item tersebut, seperti warna dan ukuran. Dengan perintah satu kata, pengguna dapat dengan mudah melakukan modifikasi yang meyakinkan pada foto yang ada.

Masa Depan Pembuat Gambar AI
Jika Anda berada di Twitter baru-baru ini, Anda pasti melihat banyak foto yang dihasilkan AI bertebaran di umpan Anda seperti penglihatan algoritmik yang aneh. Gambar-gambar ini dibuat dengan Dream, perangkat lunak baru yang memungkinkan siapa saja membuat lukisan bertenaga AI hanya dengan memberikan deskripsi singkat tentang apa yang ingin mereka lihat. Ini adalah materi yang aneh dan seringkali meresahkan yang tetap menyenangkan.
Karya akhir memiliki estetika tersendiri, yang dicirikan oleh bentuk-bentuk yang berputar dan hal-hal yang campur aduk. Namun, kecemerlangan sebenarnya adalah bahwa apa pun yang Anda masukkan, perangkat lunak akan menghasilkan sesuatu yang menarik secara visual (setidaknya sampai kita menjadi terlalu terbiasa dengan mainan ini) dan itu cocok dengan permintaan Anda dalam beberapa cara yang mengejutkan.
Perhatikan gambar di bawah ini, yang diberi judul “Arkeologi Galaksi Dengan Bintang Miskin Logam”. Aplikasi ini tidak hanya menghasilkan gambar yang merepresentasikan ukuran kosmik nebula yang mencengangkan, tetapi sorotan mirip bintang yang tersebar di sekitar kosmos terutama berwarna biru — warna yang secara ilmiah berlaku untuk bintang miskin logam karena sifat metalik memengaruhi warnanya.
Lebih banyak contoh dapat ditemukan dengan melakukan pencarian sederhana di Twitter, tetapi Anda harus benar-benar bermain-main dengan aplikasi untuk lebih memahaminya. Paling tidak, foto yang dibuatnya berukuran sempurna untuk membuat latar belakang ponsel kustom.
Aksesibilitas Dream berarti juga dimasukkan ke aplikasi baru. Ini telah digunakan untuk proyek yang lebih terarah dan permainan viral (seperti memasukkan judul tesis PhD Anda dan membagikan hasilnya). T. Kingfisher , seorang penulis dan ilustrator yang menerbitkan dengan nama Ursula Vernon, mengungkapkan komik pendek yang mereka buat menggunakan Dream dalam satu utas Twitter yang spektakuler. Karakter komiknya digambar dengan tangan, sedangkan latar belakangnya dihasilkan oleh AI, dengan aspek grafik yang berubah dan aneh yang dijelaskan oleh latar: dewa tulisan Mesir, Thoth, mengawasi perpustakaan impian.
Terlepas dari kekurangannya yang jelas, Dream memberi kita gambaran tentang seperti apa media sintetis atau yang dihasilkan AI di masa mendatang. Bagi para pendukung di bidang ini, janji teknologi adalah salah satu variasi yang tidak terbatas. Game, komik, film, dan novel, menurut mereka, semuanya akan dibuat dengan cepat sebagai tanggapan atas setiap perintah dan keinginan kita di masa depan. Dan, sementara kita masih jauh dari media seperti itu yang cocok dengan kualitas produksi manusia, aplikasi hybrid terbatas akan hadir lebih cepat dari yang Anda kira – hadir seperti di luar mimpi.
Permasalahan dengan Pembuat Gambar AI
Dalam industri sintesis gambar, 2021 telah menjadi tahun kesuksesan yang luar biasa dan kecepatan penerbitan yang hingar-bingar, dengan banjir terobosan baru dan kemajuan dalam sistem yang mampu meniru kepribadian manusia melalui rendering saraf, deepfake, dan berbagai teknik kreatif.
Namun, peneliti Jerman sekarang percaya bahwa kriteria yang digunakan untuk secara otomatis menilai realisme gambar sintetik rusak parah, dan bahwa ratusan, bahkan ribuan, peneliti yang mengandalkannya untuk menghemat uang pada evaluasi hasil berbasis manusia yang mahal mungkin berada di jalur yang salah.
Para peneliti menggunakan GAN mereka sendiri yang disetel untuk FID untuk menunjukkan bagaimana standar, Fréchet Inception Distance (FID), tidak sesuai dengan standar manusia untuk menilai gambar. Mereka menemukan bahwa FID memiliki obsesinya sendiri, yang didasarkan pada kode dasar yang tidak ada hubungannya dengan sintesis gambar, dan secara konsisten gagal memenuhi kriteria ketajaman ‘manusia’.
Selain mengklaim bahwa FID tidak cocok untuk tujuan aslinya, artikel tersebut mengklaim bahwa solusi ‘jelas’, seperti mengganti mesin internalnya dengan mesin saingan, hanya akan menukar satu set bias dengan yang lain. Menurut penulis, proyek penelitian baru diperlukan untuk menetapkan ukuran yang lebih baik untuk menilai ‘keaslian’ foto yang dihasilkan secara sintetis.
Penutup
GLIDE tidak ideal , tentu saja. Meskipun contoh-contoh yang diberikan di atas adalah kisah sukses, penelitian ini juga mengalami kemunduran. Pertanyaan tertentu, seperti menanyakan mobil beroda segitiga, tidak akan memberikan visual yang menyenangkan. Karena model difusi hanya sebagus data pelatihan, imajinasi tetap kokoh di alam manusia – setidaknya untuk saat ini.
Tim menyadari bahwa metodologi mereka mungkin mempermudah orang jahat untuk menyebarkan informasi palsu atau deepfake. Mereka hanya menerbitkan model difusi yang lebih kecil dan model CLIP bersuara yang dilatih pada kumpulan data yang difilter untuk melindungi dari situasi penggunaan seperti itu. Kode dan bobot model ini dapat diakses di halaman GitHub proyek .
Sekian artikel Zhynetrick tentang Open AI Glide Menghasilkan Gambar Fotorealistik Semoga bermanfaat.











